Introduzione: Una svolta nell'infrastruttura AI
La Cina ha ufficialmente attivato quello che viene definito il più grande pool di calcolo AI distribuito al mondo. Questa nuova infrastruttura, denominata Future Network Test Facility (FNTF), promette di rivoluzionare il modo in cui vengono addestrati i modelli di intelligenza artificiale, superando le limitazioni fisiche dei singoli data center attraverso una rete ottica ad altissima velocità. Sviluppato nel corso di oltre un decennio, il progetto mira a unificare le risorse di calcolo sparse per il paese in un unico sistema coeso.
Contesto: Il progetto FNTF
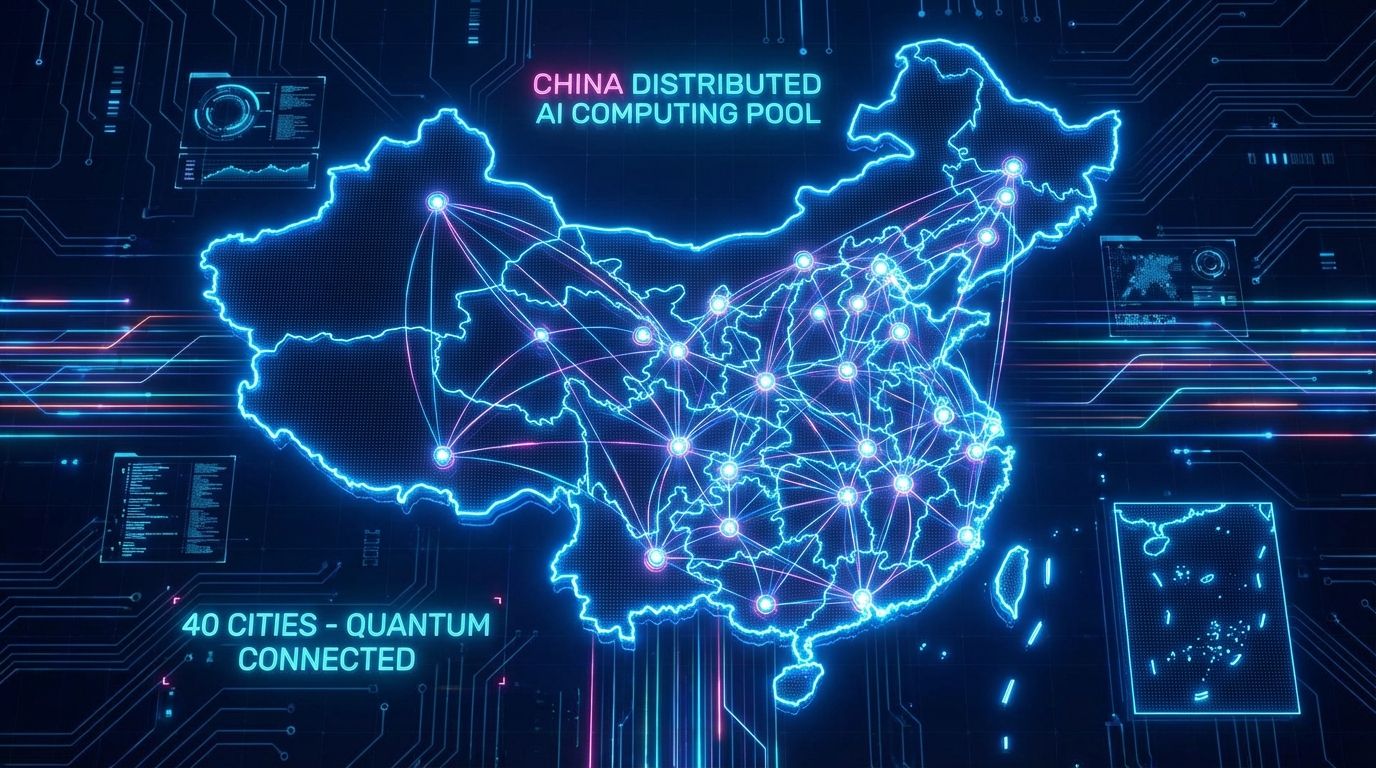
Il FNTF rappresenta il primo grande progetto infrastrutturale nazionale cinese nel settore dell'informazione e della comunicazione. Operativo dal 3 dicembre, il sistema collega centri di calcolo distanti tra loro attraverso una rete che si estende per oltre 2.000 km. La scala è impressionante: la trasmissione ottica totale supera i 55.000 km, una lunghezza sufficiente a circondare l'equatore una volta e mezza. Questa rete copre 40 città e può supportare simultaneamente 128 reti eterogenee.
Per ulteriori dettagli tecnici e geopolitici sull'argomento, è possibile consultare l'approfondimento del South China Morning Post.
"Il pool di potenza di calcolo ampio 2.000 km formato tramite questa rete potrebbe raggiungere il 98% dell'efficienza di un singolo data center."
Liu Yunjie, Membro dell'Accademia Cinese di Ingegneria
La Sfida: Latenza e coordinamento
Il problema fondamentale del calcolo distribuito è sempre stata la latenza. Quando si collegano più centri di calcolo, il tempo necessario per coordinare i dati solitamente comporta una perdita di efficienza (overhead) tra il 20% e il 40%. Questo ritardo è critico nell'addestramento dei modelli AI avanzati. L'approccio statunitense, adottato da giganti come Google o Meta (con il cluster Colossus), privilegia la concentrazione di GPU in un unico luogo per minimizzare la latenza, accettando però rischi legati al consumo energetico e alla concentrazione geografica.
Soluzione: Reti deterministiche ad alta velocità
La soluzione cinese punta su una rete deterministica che abbatte drasticamente i tempi di latenza, permettendo al pool di calcolo AI distribuito di operare quasi come un'unica entità.
- Efficienza Record: Il sistema dichiara un'efficienza del 98% rispetto a un singolo data center, eliminando quasi del tutto il collo di bottiglia della latenza.
- Velocità di Iterazione: L'addestramento di un modello AI con centinaia di miliardi di parametri richiede oltre 500.000 iterazioni. Sulla rete FNTF, ogni iterazione impiega circa 16 secondi, contro i 36+ secondi (20 secondi in più) che sarebbero necessari senza questa tecnologia. Questo si traduce in mesi risparmiati sul ciclo totale di addestramento.
- Trasferimento Dati: Durante il lancio, un set di dati da 72 terabyte generato dal telescopio FAST è stato trasmesso per 1.000 km in appena 1,6 ore. Sull'internet tradizionale, lo stesso trasferimento avrebbe richiesto circa 699 giorni.
Conclusione
Se i dati sull'efficienza del 98% verranno confermati su larga scala, la Cina potrebbe aver trovato una strategia vincente per competere nell'AI nonostante le restrizioni sui chip avanzati. Mentre gli USA puntano sulla forza bruta centralizzata, la Cina scommette sulla resilienza e sulla distribuzione geografica, trasformando la rete stessa in un supercomputer.
FAQ sul Calcolo AI Distribuito
Cos'è il pool di calcolo AI distribuito FNTF?
È un'infrastruttura cinese che collega centri di calcolo in 40 città tramite 55.000 km di fibra ottica, permettendo loro di lavorare come un unico computer per l'addestramento AI.
Quali vantaggi offre questo pool di calcolo AI distribuito rispetto ai sistemi tradizionali?
Offre un'efficienza del 98% paragonabile a un singolo data center, riducendo drasticamente i tempi di latenza e permettendo di risparmiare mesi nei cicli di addestramento dei modelli AI.
Quanto è veloce il trasferimento dati sulla nuova rete cinese?
La rete ha dimostrato di poter trasferire 72 terabyte di dati in 1,6 ore, un'operazione che richiederebbe quasi due anni (699 giorni) su una normale connessione internet.
Come si differenzia l'approccio cinese da quello statunitense?
Gli USA centralizzano le GPU in enormi data center singoli (bassa latenza ma alto consumo energetico locale), mentre la Cina distribuisce il calcolo su 2.000 km usando reti avanzate per coordinare le risorse.